Solutions
Introductie
Onderstaande stukjes code is middels copy-paste naar de GRIP-editor eenvoudig te runnen .. Zodra een connectie werkt, worden enkele grip_objecten gecreeerd in het grip_schema en werkt grip al. Bent u geinteresseerd en loopt u vast : neem contact op en we helpen u graag verder !
Etl-routines
standaard etl-routines:
trunc_insert ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 |')
insert_append ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 |')
actualize_t1 ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 | MERGE_KEYS SCHEMA_NAME,TABLE_NAME,COLUMN_NAME |')
actualize_t2 ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 | MERGE_KEYS SCHEMA_NAME,TABLE_NAME,COLUMN_NAME |')
actualize ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 | MERGE_KEYS SCHEMA_NAME,TABLE_NAME,COLUMN_NAME |')
** nb:
nog toe te voegen routine :
trunc_insert_1
insert_append_1
de 1 variant zal de id, date_created en aud_id_created ook vullen.
-
trunc_insert : de target-tabel wordt eerst geleegd, vervolgens worden de gegevens van de source in de target-tabel geladen. er zijn een 7-tal attributen die GRIP negeert uit de bron-view maar toevoegt aan de target-tabel. Deze attributen zijn de zgn. warehouse-attributen date_created, date_updated, date_deleted, aud_id_created, aud_id_updated, aud_id_deleted en curr_id.
-
insert_append : de gegevens van de source_tabel worden toegevoegd aan de target-tabel zonder trunc-vooraf.
-
actualize_t1 : de target-tabel wordt geupdate met de gegeven van de bron indien 1 of meerdere attributen anders zijn. Op basis van de MERGE_KEYS worden source en bron met elkaar gejoined terwijl de overige attributen met elkaar worden vergeleken. Indien er een of mee verschillen zijn, wordt dat target-record geupdated met het gejoinde source-record. Nieuwe voorkomens worden toegevoegd en met niet meer aangeleverde records wordt vanzelfsprekend niets gedaan. Met de date_updated en aud_id_updated worden mutaties bijgehouden. Wil men toch het warehouse opschonen van verwijderde bron-gegevens, zou dat middels een verwijder-indicator waarbij andersom-gekeken wordt of een merge_key nog wel in de bron zit. Een speciale verwijder-view draagt dan zorg voor de verwijdr-indicator.
-
actualize_t2 : Deze routine doet het zelfde als de actualize_t1, echter, in geval van een wijziging wordt het record in kwestie niet geupdate maar afgesloten : De date_deleted krijgt een timestamp van de run en aud_id_deleted krijgt het batchnummer van de run. De Curr_id krijgt de waarde 'N'. De nieuwe voorkomen van het record wordt eenvoudig toegevoegd met als date_created de timestamp van de run en de aud_id_created krijgt het batchnummer van de run.
-
actualize : Deze routine is gebasseerd op een full-aanlevering en werkt ook tiepe2, ofwel, er wordt historie opgebouwd. De merge-keys zijn niet nodig omdat onder water alle attributen meegenomen worden als merge-key.
Algemeen geldt :
- date_created en aud_id_created worden gebruikt bij een nieuw voorkomen, de curr_id wordt op 'Y' gezet.
- date_updated en aud_id_updated worden gebruikt indien een voorkomen geupdate wordt.
- date_deleted en aud_id_deleted worden gebruikt bij het afsluiten van een voorkomen. de curr_id wordt op 'N' gezet.
RID-etl-routines
Hieronder volgen een 3-tal RID-routines, ontstaan vanuit de oracle-hoek. Het is een indirecte maar veilige manier van updaten en deleten: tijdens het ontwikkelen bepaal je de set van te raken records. Door deze business-logica in een view vast te leggen, en aan te bieden in de ETL-aanroep, zorgt GRIP verder voor het processen en registreren en foutafhandeling. Afhankelijk van het database-systeem, levert de view de meest efficiente uniek-key waardoor het proces weet welke record verwijderd of geupdate moet worden. In geval van de update levert de view onder de attributen de gewenste waarde, welke vervolgens geupdate zullen worden. In de rid_update regeert het proces niet op eventuele extra attributen.
rid_delete ('| SOURCE DEMO_RID_DELETE_ORA_V | TARGET DEMO_RID_DELETE | SHOWCODE | SHOWRES | NO_UPDUPD |')
rid_update ('| SOURCE DEMO_RID_DELETE_ORA_V | TARGET DEMO_RID_DELETE | SHOWCODE | SHOWRES | NO_UPDUPD |')
rid_delete_fysiek ('| SOURCE DEMO_RID_DELETE_ORA_V | TARGET DEMO_RID_DELETE | SHOWCODE | SHOWRES |')
Voor oracle wordt de ROWid gebruikt, Sqlserver heeft weer een andere feature.. hier een voorbeeld voor oracle:
#maak een demo-temp-tabel
trunc_insert ("| SOURCE GRIP_METADATA_V | TARGET DEMO_RID_DELETE | WHERE table_name = 'GRIP_LOG' | SHOWCODE | ")
CREATE OR REPLACE VIEW xxx.DEMO_RID_DELETE_ORA_V
as
select x.rowid RID, 'geupdate_' || lower(column_name) column_name
from DEMO_RID_DELETE x
where table_name = 'GRIP_LOG'
and curr_id = 'Y'
# bestudeer de uitvoer
select * from xxx.DEMO_RID_DELETE_ORA_V
# voer de update uit:
rid_update ('| SOURCE DEMO_RID_DELETE_ORA_V | TARGET DEMO_RID_DELETE | SHOWCODE | SHOWRES |')
#controleer eerste 2 kolommen en column_name
select curr_id, date_deleted, x.* from xxx.DEMO_RID_DELETE x where table_name = 'GRIP_LOG'
# voer de delete uit:
rid_delete ('| SOURCE DEMO_RID_DELETE_ORA_V | TARGET DEMO_RID_DELETE | SHOWCODE | SHOWRES |')
#controleer eerste 2 kolommen
select curr_id, date_deleted, x.* from xxx.DEMO_RID_DELETE x where table_name = 'GRIP_LOG'
# voer onderstaande stap uit .. vanwege de rid_delete staat de curr__id op 'N' en zal er geen delete plaat vinden.
rid_delete_fysiek('| SOURCE DEMO_RID_DELETE_ORA_V | TARGET DEMO_RID_DELETE | SHOWCODE | SHOWRES |')
# opruimen temp-tabellen
drop view xxx.DEMO_RID_DELETE_ORA_V
drop table xxx.DEMO_RID_DELETE
DROP_TEMP_TABLES
- NO_UPDUPD : indien geset, dan wordt de date_update en aud_id_updated niet bepaald. Sommige vervolg-etl selecteert op basis van de gewijzigde brondata
waardoor je een stuwing van mutaties krijgt .. Stel dat je een update doorvoert over alle records, waarbij je geen date_updated niet wil raken, is deze optie erg handig.
Het doorpropageren van mutaties dempt daarmee.
Voor sqlserver geldt een andere syntax, hieronder een voorbeeld ..
trunc_insert ("| SOURCE GRIP_METADATA_V | TARGET DEMO_RID_DELETE | WHERE table_name = 'GRIP_LOG' | SHOWCODE | ")
CREATE VIEW xxx.DEMO_RID_DELETE_SSS_V
as
select %%physloc%% RID, 'geupdate_' + lower(column_name) as column_name
from xxx.DEMO_RID_DELETE
where table_name = 'GRIP_LOG'
and curr_id = 'Y'
DROP VIEW grip.DEMO_RID_DELETE_SSS_V
# bestudeer de uitvoer
select * from xxx.DEMO_RID_DELETE_SSS_V
# voer de update uit:
rid_update ('| SOURCE DEMO_RID_DELETE_SSS_V | TARGET DEMO_RID_DELETE | SHOWCODE | SHOWRES | ')
#controleer eerste 2 kolommen en column_name
select curr_id, date_deleted, x.* from xxx.DEMO_RID_DELETE x where table_name = 'GRIP_LOG'
# voer de delete uit:
rid_delete ('| SOURCE DEMO_RID_DELETE_SSS_V | TARGET DEMO_RID_DELETE | SHOWCODE | SHOWRES | ')
#controleer eerste 2 kolommen
select curr_id, date_deleted, x.* from xxx.DEMO_RID_DELETE x where table_name = 'GRIP_LOG'
#
rid_delete_fysiek ('| SOURCE DEMO_RID_DELETE_SSS_V | TARGET DEMO_RID_DELETE | SHOWCODE | SHOWRES | ')
#
select curr_id, date_deleted, x.* from xxx.DEMO_RID_DELETE x where table_name = 'GRIP_LOG'
# opruimen temp-tabellen
drop view xxx.DEMO_RID_DELETE_SSS_V
drop table xxx.DEMO_RID_DELETE
DROP_TEMP_TABLES
Voor postgresql geldt een andere syntax en dus ook een andere RID-view:
# maak een demo-temp-tabel
trunc_insert ("| SOURCE GRIP_METADATA_V | TARGET DEMO_RID_DELETE | WHERE table_name = 'GRIP_LOG' | SHOWCODE | ")
# maak de RID-view
CREATE or replace VIEW xxx.DEMO_RID_DELETE_PG_V
as
select SCHEMA_NAME,TABLE_NAME,COLUMN_NAME , 'geupdate_' || lower(data_type) data_type
from xxx.DEMO_RID_DELETE
where table_name = 'GRIP_LOG'
and curr_id = 'Y'
# bestudeer de uitvoer
select * from xxx.DEMO_RID_DELETE_PG_V
# voer de update uit:
rid_update ('| SOURCE DEMO_RID_DELETE_PG_V | TARGET DEMO_RID_DELETE | SHOWCODE | SHOWRES | MERGE_KEYS SCHEMA_NAME,TABLE_NAME,COLUMN_NAME | ')
#controleer eerste 2 kolommen en column_name
select curr_id, date_deleted, x.* from xxx.DEMO_RID_DELETE x where table_name = 'GRIP_LOG'
# voer de delete uit:
rid_delete ('| SOURCE DEMO_RID_DELETE_PG_V | TARGET DEMO_RID_DELETE | SHOWCODE | SHOWRES | MERGE_KEYS SCHEMA_NAME,TABLE_NAME,COLUMN_NAME | ')
#controleer eerste 2 kolommen
select curr_id, date_deleted, x.* from xxx.DEMO_RID_DELETE x where table_name = 'GRIP_LOG'
#
rid_delete_fysiek ('| SOURCE DEMO_RID_DELETE_PG_V | TARGET DEMO_RID_DELETE | MERGE_KEYS SCHEMA_NAME,TABLE_NAME,COLUMN_NAME | ')
#
select curr_id, date_deleted, x.* from xxx.DEMO_RID_DELETE x where table_name = 'GRIP_LOG'
# opruimen temp-tabellen
drop view xxx.DEMO_RID_DELETE_PG_V
drop table xxx.DEMO_RID_DELETE
DROP_TEMP_TABLES
specials worden verder op besproken, de specials zijn:
actualize_hub ('||')
actualize_link ('||')
table_compare ('||')
de ETL-routines kunnen een of meerdere parameters meekrijgen :
met de parameters stel je het etl-proces in of kun je het proces aanvullen ...
-- DEBUG <'',1,3,9> per ETL-stap wordt de gegenereerde ETLcode getoond
-- SHOWRES na de ETL worden de LOG en AUD-gegevens getoond
-- SHOWCODE na de ETL wordt de gegenereerde code getoond
-- 2JOB de code wordt niet uitgevoerd maar als een schedule-job geplaatst voor verwerking
-- MERGE_KEYS die attributen die een record uniek maakt, een of meer functionele attributen of een ID
LAST_DATE_PROCESSED
Om niet de gehele dataset over te hoeven halen, kan middels 'LAST_DATE_PROCESSED' een delta dataset overgehaald worden. Omdat in de tabel GRIP_AUD alle succesvolle ETL gelogd wordt, kan middels een lookup het laatste bron-target voorkomen opgezocht worden. Diens 'START_DT' is het tijdstip voor de filtering : gegevens van 'NA' dit tijdstip worden met de huidige select opgehaald. Middels deze constructie worden alleen nieuwe gegevens pgehaald. Wil men vanwege een storing toch meer records terug in de tijd op willen halen, dan kan dat middels de parameters DAYSBACK, MINUTESBACK of SECONDSBACK. Het attribuut waar de LAST_DATE_PROCESSED op gaat filteren kan voorzien worden van een index voor optimale performance.
Voorbeeld van aanroep:
trunc_insert("| SOURCE GRIP_AUD | TARGET GRIP_AUD_TST1 | LAST_DATE_PROCESSED START_DT | DAYSBACK 10 | ")
trunc_insert("| SOURCE GRIP_AUD | TARGET GRIP_AUD_TST1 | LAST_DATE_PROCESSED START_DT | MINUTESBACK 10 | ")
trunc_insert("| SOURCE GRIP_AUD | TARGET GRIP_AUD_TST1 | LAST_DATE_PROCESSED START_DT | SECONDSBACK 10 | ")
** NB: statischere oplossing:
trunc_insert("| SOURCE GRIP_AUD | TARGET GRIP_AUD_TST1 | WHERE DATE_CREATED > sysdate -9 | ")
Database naar Database
NB: voer voor pg_duitsland uw connectie in.
data van SOURCE_DB naar TARGET_DB kopieerbaar, dus van bv oracle naar sqlserver
query_2_db('| SOURCE GRIP_LOG | TARGET GRIP_LOG_DEMO | WHERE 2=2 | ')
query_2_db('| SOURCE GRIP_LOG | TARGET GRIP_LOG_DEMO | SOURCE_DB pg_duitsland | TARGET_DB pg_duitsland | WHERE 2=2 | ')
query_2_db('| SOURCE GRIP_LOG | TARGET GRIP_LOG_DEMO | SOURCE_DB pg_duitsland | TARGET_DB pg_duitsland | WHERE 2=2 limit 1000 | SHOWCODE | ')
query_2_db ('| SOURCE GRIP_DATUM_V | TARGET GRIP_DATUM_DEMO | SOURCE_DB pg_duitsland | TARGET_DB pg_duitsland | LOG_INFO 190 seconden | ')
query_2_fs_db ('| SOURCE GRIP_DATUM_V | DIRECTORY c:\data | TARGET GRIP_DATUM_DEMO | BUCKET 20000 | TIMES 10 | SOURCE_DB pg_duitsland | TARGET_DB pg_duitsland |')
bulk_loader ('| SOURCE GRIP_DATUM_V | TARGET GRIP_DATUM_DEMO | BUCKET 12000 | ITERATIE 50 | xDEBUG | xSHOW | COMMIT | LOAD | SOURCE_DB pg_duitsland | TARGET_DB pg_duitsland | ')
NB: target wordt aangemaakt op basis van aangeboden data
Targettabel wordt vooraf geleegd
Data gaat via memory van de GRIP-computer hetgeen een beperking heeft in memory ..
Database to csv
query_2_fs schrijft data weg naar het filsystem, verdeeld in porties van bucket-grootte. De bestanden krijgen de numerieke extentie als
rdw_voertuigen_0001.csv
rdw_voertuigen_0002.csv
rdw_voertuigen_0003.csv
rdw_voertuigen_0004.csv
De naamgeving van de TARGET-csv-bestanden zijn bij inlezen weer de naam van de TARGET-tabel in de target-database.
record_on('PF_Q2FS')
query_2_fs ('| SOURCE dbo.rdw_voertuigen | DIRECTORY c:\data | TARGET rdw_voertuigen | BUCKET 1000 | TIMES 10| SOURCE_DB SS_boss | TARGET_DB SS_GWH_login1 |')
query_to_csv( '| SOURCE grip.GRIP_LOG | TARGET c:/data/demo_dump_postgresql.csv | SHOW | ')
record_off()
flow_run('| FLOW PF_Q2FS |')
Call, Bcall en Ecall
Middels de CALL kan een 'procedure' gestart worden. De procedure zit ergens in de current-source. Is als extra parameter
Middels de ECALL kan een commando in een parrallel GRIP.exe uitgevoerd worden. Met de ECALL kan bv een zware flow gestart worden terwijl de ontwikkelomgeving beschikbaar blijft voor doorontwikkeling.
CALL PF_LABEL <SOURCE>
BCALL PF_LABEL <SOURCE>
ECALL <COMMAND>
BEGIN PF_LABEL
DISP demo aanroep van een procedure 1
DISP demo aanroep van een procedure 1
DISP demo aanroep van een procedure 1
DISP demo aanroep van een procedure 1
CALL PF_LABEL_NEXT
RETURN
BEGIN PF_LABEL_NEXT
DISP demo aanroep van een procedure NEXT
DISP demo aanroep van een procedure NEXT
DISP demo aanroep van een procedure NEXT
DISP demo aanroep van een procedure NEXT
SLEEP 5
RETURN
middels onderstaande worden 4 parrallele SLEEPS opgestart:
ECALL SLEEP 10
ECALL SLEEP 10
ECALL SLEEP 10
ECALL SLEEP 10
Specials
- ODBC Om eenvoudig de beschikbare ODBCADMIN64 dsn-drivers te lijsten. De naam van de driver kan in de grip_con.dat opgenomen worden.
- DROP_TEMP_TABLES Indien een ETL-functie tijdens ontwikkelen in error geraakt, blijven temptabellen achter. Middels deze routine worden de temptabellen opgeruimd.
- INSTALL GRIP heeft een aantal objecten nodig in het geconnecte schema. Middels INSTALL worden deze objecten gehercreerd indien ze niet meer bestaan.
- UNINSTALL Genereert een script voor verwijderen van de objecten van grip. Script kan uitgevoerd worden.
- DROPGRIP of UNINSTALL Er wordt een script gegenereerd in de logging welke gecopieerd kan worden om uitgevoerd te worden in de editor.
- HELP Geeft een sumiere help in het logging-scherm
- REPEAT 10
wanneer REPEAT 10 voor het commando geplaatst wordt, zal het commando 10 keer uitgevoerd worden. In de commando-regel kan het token <REPEAT> opgenomen worden ..
Per iteratie wordt
trunc_insert ('| SOURCE GRIP_METADATA_V | TARGET MY_TARGET<REPEAT> | WHERE
probeer de volgende aanroepen uit:
ODBC
DROPGRIP
UNINSTALL
REFRESH
REPEAT 10 DISP <CNT>
DROP_TEMP_TABLES
INSTALL
ADD_COLS <table>
VERSIEBEHEER
SHOW CURRENT_DIR
SCANTAB wildcard
scantab CBS DISP <SCANTAB>
scantab * DISP <SCANTAB>
scantab CBS table_scanner('| SOURCE <SCANTAB> | TARGET STG_PDF_NOUNS1 | DATA_TYPE TEXT,VARCHAR | TYPE NOUN | CONTEXT AVG | LOCATION nvt | |')
scantab * trunc_insert('| SOURCE <SCANTAB> | TARGET STG_<SCANTAB> | LOGINFO bron-replicatie <SCANTAB> |')
rownorow
voor copy-paste is de rownumber van de dataset niet wenselijk. Middels rownorow kan het regelnummer aan en uitgezet worden.
clipboard
middels clipboard kan het clipboard aan en uitgezet worden.
Parameters
- Met de parameters kunnen variabelen gecreerd worden voor het opslaan van waarden. Deze parameters kunnen vervolgens views/ETL's geraadplaagd worden. Te denken is aan bijvoorbeeld "Last_day_processed" variabele voor selecteren van alleen nieuwere voorkomens tov de vorige LOAD. Een parameter kent 3 types: de NUMBER, CHAR en de DATE. De parameters vind je terug in tabel xxx.grip_para.
SET PARA WOONPLAATS CHAR LEEK
SET PARA WOONPLAATS NUM 1963
SET PARA WOONPLAATS DATE 1963-04-20
SET PARA WOONPLAATS DESC Omschrijving van de parameter
SHOW PARA WOONPLAATS
- drop para MKDOCS_% : verwijderen van parameters die beginnen met ...
- drop para MKDOCS : verwijderen van parameters die MKDOCS heet.
- select * from xxx.grip_para : voor tonen van de parameters.
Flow
- record_on('| FLOW MYFLOW |')
- record_off()
Middels flow_run kan een flow gestart of doorgestart worden. Alle commando's tussen record_on( '| FLOW MYFLOW |' ) .. en record_off() worden opgenomen als JOB van de flow MYFLOW. Een JOB kan een willekeurige ETL-routine zijn maar kan ook een willekeurig ander commando zijn als bv. SET DBF postgresql. De jobs worden in volgorde van definitie opgelagen in tabel GRIP_JOB. Met record_on() wordt de vorige/huidige definitie geheel verwijderd en wordt de nieuwe geheel geladen. De command's zullen NIET hun werk doen tijdens de record_on-modus.
-- aanmaken van een flow
record_on('| FLOW PF_TESTFLOW |')
trunc_insert ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 |')
insert_append ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 |')
actualize_t1 ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 | MERGE_KEYS SCHEMA_NAME,TABLE_NAME,COLUMN_NAME |')
actualize_t2 ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 | MERGE_KEYS SCHEMA_NAME,TABLE_NAME,COLUMN_NAME |')
actualize ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 | MERGE_KEYS SCHEMA_NAME,TABLE_NAME,COLUMN_NAME |')
record_off( )
-- starten van de flow
flow_run('| FLOW PF_TESTFLOW |')
-- kijken naar de inhoud
select * from xxx.grip_job where parent = 'PF_TESTFLOW'
select * from xxx.grip_job_run where MAINFLOW = 'PF_TESTFLOW'
-- met een lege record_on/off wordt de flow-definitie verwijderd.
record_on('| FLOW PF_TESTFLOW |')
record_off( )
- FLOW_RUN('| FLOW MYFLOW |')
Middels flow_run kan een flow gestart of doorgestart worden. Van de flow zoals hij gedefinieerd is in GRIP_JOB wordt een kopie geplaatst in tabel GRIP_JOB_RUN indien deze daar nog niet in voorkomt.
In deze tabel geeft 'STATUS' de status van de jobs weer. De volgorde wordt weergegeven met VNR en de FNR geeft het unieke nummer weer van de FLOW-run. Met het uitvoeren van flow_run() wordt gekeken
of er niet nog een dergelijke flow gaande is, en zoja, dan wordt naar de status van de job met de laagste VNR gekeken:
| Status | Toelichting |
|---|---|
| Selected_for_start | De job met de laagste volgordenummer ( VNR ) wordt geselecteerd voor Running |
| Skipped | Deze job is in 'Skipped' gezet met FLOW_SKIP_ERROR('! FLOW MYFLOW !') |
| Running | De job met deze status wordt uitgevoerd |
| Ready | Deze job is gereed |
| Error | Indien een job in error komt, wordt de status op 'Error' gezet. |
Indien een flow gestart wordt, met flow_run(), en een van de jobs heeft 'running', dan wordt de melding gemaakt "FLOW loopt reeds.". Indien een van de jobs in 'Error' staat
dan wordt met flow_run de flow opgestart vanaf de job in 'Error' : deze wordt doorgestart. Wanneer de laatste job op 'Ready' is gezet, wordt de flow automatisch opgeruimd: de FLOW-records in GRIP_JOB_RUN
worden verplaatst naar GRIP_JOB_RUN_HIST.
- FLOW_DROP
Een 'Running' flow of een flow in 'Error' wordt opgeruimd: de FLOW-records in GRIP_JOB_RUN worden verplaatst naar GRIP_JOB_RUN_HIST. De flow_drop wordt uitgevoerd indien de 'halve flow' as-is opgeruimd mag worden.
- FLOW_SKIP_ERROR
Indien een flow in error staat en de job in kwestie mag geskipped, kan middels flow_skip_error de flow doorgestart worden bij de volgende job. De current-job die in 'Error' staat wordt in 'Skipped' gezet.
- FLOW_INFO ('| ALL DEF RUN |')
Dit commando geeft inzicht in de JOBS
| code | Toelichting |
|---|---|
| ALL | de running flows, uitgebreide weergave met alle jobs per flow |
| DEF | de gedefinieerde flows |
| RUN | de running flows, compacte weergave met subset aan jobs per flow |
Onderstaande geeft een voorbeeld van een FLOW die in error geraakt. De oorzaak van de fout kan gefixed waarna de flow doorgestart kan worden.
Wil men de flow doorstarten en later de fout fixen, kan dat middels flow_skip_error ('| flow |')
# aanmaak van een flow met een syntaxt-error
record_on('| FLOW PF_TESTFLOW_WITH_ERROR |')
trunc_insert ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 | ')
insert_append ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 | WHERE 1=@@SYNTAXERROR@@ | ')
actualize_t1 ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 | MERGE_KEYS SCHEMA_NAME,TABLE_NAME,COLUMN_NAME |')
actualize_t2 ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 | MERGE_KEYS SCHEMA_NAME,TABLE_NAME,COLUMN_NAME |')
actualize ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 | MERGE_KEYS SCHEMA_NAME,TABLE_NAME,COLUMN_NAME |')
record_off( )
# run the flow and monitor the error-handling
#
flow_run('| FLOW PF_TESTFLOW_WITH_ERROR |')
# show the flows running or in error
#
flow_info ( '| ALL |' )
# doorstarten van de flow met een SKIP-error
flow_skip_error ( '| FLOW PF_TESTFLOW |')
#
record_on('| FLOW PF_TESTFLOW_WITH_ERROR_NOGEEN |')
trunc_insert ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 | ')
insert_append ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 | WHERE 1=@@SYNTAXERROR@@ | ')
actualize_t1 ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 | MERGE_KEYS SCHEMA_NAME,TABLE_NAME,COLUMN_NAME |')
actualize_t2 ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 | MERGE_KEYS SCHEMA_NAME,TABLE_NAME,COLUMN_NAME |')
actualize ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 | MERGE_KEYS SCHEMA_NAME,TABLE_NAME,COLUMN_NAME |')
record_off( )
# run de flow en kijk hoe de 2 flows in error staan.
flow_run('| FLOW PF_TESTFLOW_WITH_ERROR_NOGEEN |')
# show the flows running or in error
#
flow_info ( '| xALL |' )
# fix or skip the job in error.. and continue the flow
#
flow_skip_error ( '| FLOW PF_TESTFLOW_WITH_ERROR |')
flow_skip_error ( '| FLOW PF_TESTFLOW_WITH_ERROR_NOGEEN |')
# commands voor inzicht in de flows ..
show flow
show flow all
show flow run
show flow def
Bulk loaders
- query_2_fs_db zorgt ervoor dat een hele grote tabel als csv gedumpt wordt op het filesystem.
DIRECTORY : directory waar de csv's gedumpt worden.
SOURCE : de naam van de tabel of URL ( http:// )
TARGET : de naam van het doel-bestand / tabel , in onderstaand is rdw_voertuigen de prefix van de csv maar later ook de naam van de target-tabel
TIMES : in combinatie met bucket kan met bijvoorbeeld 100 bestanden van 100000 records dumpen
BUCKET : de hoeveelheid records per csv.
DELIMITER : ,;'pipe of tab seperator tussen de velden.
SHOW : tonen debug-informatie
query_2_fs_db ('| SOURCE dbo.rdw_voertuigen | DIRECTORY c:\data | TARGET rdw_voertuigen
| BUCKET 100 | TIMES 10 | SOURCE_DB SS_boss | TARGET_DB SS_GWH_login1 |')
- bulk_insert, speciaal voor sqlserver. Let daarbij op dat wanneer je een linux-sqlserver hebt, diens file-system naamgeving dient te gebruiken.
grip_aux.bulk_insert ('| SOURCE c:/data/rdw_voertuigen_JAG_00001.csv | TARGET JAGGER | ')
BULK INSERT grip.JAGGER1112
FROM 'c:/data/rdw_voertuigen_00001.csv'
WITH ( DATAFILETYPE = 'char'
,FIELDTERMINATOR = '|'
,ROWTERMINATOR = '0x0a'
,FIRSTROW = 1
,KEEPNULLS
)
- bulk_loader, voor overpompen van data van de ene database naar de andere. De data gaat via de computer waarop GRIP.EXE draait.
SOURCE : de bron-tabel of views/ETL
TARGET : de target-tabel.
ITERATIE : aantal fetches van een bucket ( default 100000 )
BUCKET : aantal records per iteratie ( default 5000 )
ARRAY : buffer ( default 5000 )
COMMIT : indien aanwezig, dan een commit per iteratie
SHOW : toon doorloop in seconden per iteratie
DEBUG : toont debug-info
TARGET_DB : target-connectie
SOURCE_DB : source-connectie
bulk_loader ('| SOURCE GRIP_LOG | TARGET JAGGER1214 | BUCKET 100 | ITERATIE 100 | xDEBUG | SHOW | COMMIT
| TARGET_DB SS_GWH_login1 | SOURCE_DB SS_GWH_login1 | ')
Analyze-data
Op basis van scannen van bijvoorbeeld 500 csv-regels, gaat de routine het datatype vaststellen. Indien een bepaalde kolom alleen NUMBERS heeft, behalve 1, wordt het type alsnog VARCHAR. Middels ACTION STATS krijg je inzicht in de hoeveelheid datatypen per kolom. Indien bijvoorbeeld NUMBER 99% van toepassing is, zou je de bron kunnen aanpassen op 100% Numbers .. . Het datum-formaat kan als een lijst van formaten opgegeven worden.
- SOURCE filename of csv.
- TARGET table_name for createscript of table
- ACTION PRINT,STATS,CREATE
- DELIMITER delimiter [ , ; tab pipe ]
- ROWNUM subset
- SHOW display processed rows and types guessed..
- DBF_TYPE generate createscript for specific database [ oracle,sqlserver,snowflake,postgresql ]
- DATE_FORMAT list of formats eg. [ %Y-%m-%d, %Y%m%d ] nb. formats of python/datetime/strptime or [ %Y-%m-%d %H:%M:%S.%f, %Y-%m-%d %H:%M:%S ]
- COL_LENGTH for oracle, columnnames are max 30 characters.
analyze_csv( '| SOURCE c:/data/grip_aud_sqlserver.csv | DELIMITER pipe | SHOW | ACTION PRINT | DBF_TYPE oracle | DATE_FORMAT %Y-%m-%d %H:%M:%S.%f, %Y-%m-%d %H:%M:%S | ROWNUM 500 | ')
analyze_csv( '| SOURCE c:/data/grip_job_sqlserver.csv | DELIMITER ; | SHOW | ACTION PRINT | DBF_TYPE oracle | DATE_FORMAT %Y-%m-%d %H:%M:%S.%f, %Y-%m-%d %H:%M:%S | ROWNUM 500 | ')
Scheduler
Middels de scheduler kunnen o.a. flows op een bepaald moment gestart worden. Als frequentie kan gekozen worden uit
- SECONDS, MINUTES, HOURS
- DAY
- MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY en SUNDAY
Bij de laatste 2 categorien kan middels parameter HH24MI het tijdstip van die dag gekozen worden. Bij de eerste categorie kan met VALUE de iteratie aangegeven worden.
add_sched ( "| CODE 011 | DESCR Demo-Job 11 | FREQ SECONDS | VALUE 15 | STATUS OFFLINE | COMMAND flow_run('| FLOW PF_TESTFLOW |') | QUICK ||" )
add_sched ( "| CODE 012 | DESCR Demo-Job 12 | FREQ DAY | HH24MI 14:00 | STATUS ONLINE | COMMAND SLEEP 4 | QUICK |" )
add_sched ( "| CODE 013 | DESCR Demo-Job 13 | FREQ TUESDAY | HH24MI 14:00 | STATUS ONLINE | COMMAND DISP Demo tekst |" )
add_sched ( "| CODE 014 | DESCR Demo-Job 14 | FREQ SUNDAY | HH24MI 1:00 | STATUS ONLINE | COMMAND flow_run('| FLOW PF_TESTFLOW |') |" )
- start_i_sched( 4 ) : starten van de scheduler met een interval van 10 seconden. Na 4 iteraties stopt de scheduler.
-
start_sched : de scheduler wordt gestart in een opgestartte grip.exe en komt in een oneindige lus. Om de 10 seconden wordt gekeken naar een nieuwe aanroep.
-
drop_sched( '999') : de scheduler wordt beeindigd.
-
select * from xxx.grip_sched : tonen van de aanwezige jobs.
middels parameter QUICK wordt de job in de current scheduler uitgevoerd, hetgeen een snelle start geeft. Zonder QUICK wordt de job in een op te starten grip.exe uitgevoerd. Zodra de JOB klaar is, verdwijnt de grip.exe weer uit het geheugen.
- FREQ : SECONDE,MINUTES,HOUR,DAY,MONDAY.. SUNDAY
- TIME : hh:mm ( bv 14:05 ), heeft geen zin bij SECONDS of MINUTES
- VALUE : 1..99 voor seconds of minutes of hours
- COMMANDS : de commando die uitgevoerd kunnen worden.
** Let op de dubbele quotes tbv van COMMAND.
Csv,json,rss
- csv_to_stage is er voor het laden van CSV-bestanden in de database. Indien de target-tabel niet bestaat, wordt ie aangemaakt op basis van de gesameplde structuur van de waarden. Voert men extra parameter DIRECTORY en WILDCARD toe, worden meerdere directories en bestandsoorten opgepakt en verwerkt met csv_to_stage.
SOURCE : bestaand csv-file ( bestand of URL )
TARGET : doeltabel, wordt automatisch aangemaakt op basis van inhoud met type-guess
SHOW : tonen van CSV-regels met type guess aaneggeven
ROWNUM : aantal te verwerken regels
DELIMITER : field-seperator , : ; pipe tab
APPEND : de CSV-data wordt toegevoegd aan de TARGET-tabel
csv_to_stage( ' | SOURCE c:/data/rdw_gebreken.csv
| TARGET STG_RDW_GEBREKEN | DELIMITER , | LOG_INFO inlezen rdw voertuigen | SHOW | ' )
csv_to_stage( ' | SOURCE https://opendata.rdw.nl/resource/m9d7-ebf2.csv | TARGET STG_RDW_GEK_VOERTUIGEN
| DELIMITER , | LOG_INFO inlezen rdw voertuigen | xSHOW | ' )
- json_to_stage voor het laden van json data in de database.
SOURCE : bestaand csv-file ( bestand of URL )
TARGET : doeltabel, wordt automatisch aangemaakt op basis van inhoud met type-guess
SHOW : tonen van CSV-regels met type guess aaneggeven
ROWNUM : aantal te verwerken regels
DELIMITER : field-seperator , : ; pipe tab
APPEND : de CSV-data wordt toegevoegd aan de TARGET-tabel
json_to_stage( ' | SOURCE https://opendata.rdw.nl/resource/gx6w-afwf.json | TARGET STG_RDW_VOERTUIGEN
| LOG_INFO Gekentekende voertuigen | SHOW | ' )
- rss_to_stage Met deze functie kunnen rss-feeds ingelezen worden.
SOURCE : bestaand csv-file ( bestand of URL )
TARGET : doeltabel, wordt automatisch aangemaakt op basis van inhoud met type-guess
SHOW : tonen de data in panda's weergave
APPEND : de CSV-data wordt toegevoegd aan de TARGET-tabel
record_on('PF_RSS')
rss_to_stage ( '| SOURCE https://www.ad.nl/reizen/rss.xml | TARGET STG_RSS_REIZEN | SHOW |' )
rss_to_stage ( '| SOURCE http://www.ictvacaturemarkt.nl/rss/ict-beheer/ | TARGET STG_RSS_VACATURES | SHOW |' )
rss_to_stage ( '| SOURCE https://www.nu.nl/rss/economie | TARGET STG_RSS_NU | SHOW |' )
rss_to_stage ( '| SOURCE https://www.who.int/rss-feeds/news-english.xml | TARGET STG_RSS_WHO_NEWS | SHOW |' )
record_off()
flow_run('| FLOW PF_RSS | ')
select * from xxx.STG_RSS_NU
Show
| SHOW | ITEM | ITEM | Toelichting |
|---|---|---|---|
| SHOW | DBF | toont current connection parameters en overige mogelijke connections | |
| TABLES | de tabellen van current schema | ||
| VIEWS | de views van current schema | ||
| ALL | alle tabellen en views van current schema | ||
| TOTAL | toont alle views en tabellen waar op geselecteerd mag worden | ||
| CODE | de gegenereerde sql-code van de laatst uitgevoerde ETL | ||
| FLOW | 'flow' | toon info van running 'flow' | |
| FLOW | toon info van current flows | ||
| DDL | 'view' 'table' | toon createscripts van tabellen en views | |
| DICT | 'table' 'schema' | toon createscripts van tabel uit schema | |
| DICT | 'schema' | toon createscripts van alle tabellen en views uit schema | |
| DICT | toon createscripts van alle tabellen en views van current connection | ||
| PARA | 'code' | toon waarden van parameter 'code' | |
| PARA | toon waarden van alle parameters | ||
| 'list' | tonen van de laatste 10 records van de tabellen uit GRIP-tabellen-list : 'GRIP_LOG','GRIP_AUD','GRIP_JOB', 'GRIP_DEBUG','GRIP_JOB_RUN','GRIP_JOB_RUN_HIST','GRIP_PARA' |
||
| CURRENT_DIR | toon huidige directory | ||
| COLS,SELECT | 'table' of 'view' | toon select query van tabel |
Data-grabbers
PDF-grabbers
Middels de PDF-scanner kunnen PDF-bestanden gelezen worden op inhoud waarbij de text als leesbaar in een tabel opgeslagen wordt maar ook als losse woorden met daarbij het aantal keren dat ze voorkomen. Zodoende kan er een cross-reference aangelegd worden en kan met bijvoorbeeld zoeken op "Powerbi" waarna alle CVs gelijst kunnen worden met mensen met kennis van Powerbi. De target-tabel wordt gemaakt indien deze niet bestaat. Met vervolg-ETL kan doorgequeried worden op de aangelegde metadata. Ook kan een directory opgegeven worden zodat alle bestanden verwerkt worden die volgens de wildcard matchen. Zowel voor de directory als wildcarsd kunnen meerdere opgegeven worden, met als delimeter de comma.
pdf_scanner('| SOURCE c:\data\Jansonius, Dolf (00002498) - CV 2015.pdf | TARGET STG_PDF_TEXT | TYPE TEXT | CONTEXT CV | LOCATION sollicitaties | SHOW |')
pdf_scanner('| SOURCE c:\data\Jansonius, Dolf (00002498) - CV 2015.pdf | TARGET STG_PDF_NOUNS | TYPE NOUN | CONTEXT CV | LOCATION sollicitaties | |')
pdf_scanner('| DIRECTORY c:\data | WILDCARD *.pdf | TARGET JANSO1 | TYPE NOUN | SHOW |')
pdf_scanner('| DIRECTORY c:\grip\admin\facturen | WILDCARD *.pdf | TARGET JANSO1 | TYPE NOUN | SHOW |')
plot_query ('| QUERY select NOUN , AANTAL from xxx.STG_PDF_NOUNS where aantal > 20 | KIND bar | X_AS NOUN | Y_AS AANTAL |')
TABLE-grabbers
Middels de table-scanner kunnen tabellen op inhoud gescanned worden. De inhoud van de "kolommen" wordt als noun beschouwd en het aantal voorkomens ervan wordt opgeslagen in de tabel. Op deze wijze wordt een cross-reference aangelegd van waaruit je kunt zoeken naar tabellen/sources in je tabellen-verzameling. Middels CONTEXT kan aan gegeven worden tot welke CONTEXT de waarden behoren ... Zodoende kunnen gevonden nouns in verschillende tabellen verschillende context-labels krijgen en kun je over contexten querien ... Indien een tabel/column nouns heeft met uitsluitend voorkomens heeft met aantal=1, betekent dat dat deze kolom unieke waarden bevat die geschikt zijn voor een unieke sleutel.
table_scanner('| SOURCE GRIP_METADATA_V | TARGET STG_PDF_NOUNS1 | DATA_TYPE TEXT,VARCHAR | TYPE NOUN | CONTEXT NOUNS | LOCATION nvt | |')
table_scanner('| SOURCE GRIP_METADATA_V | TARGET STG_PDF_NOUNS1 | COLUMNS VOORKEUR,COLUMN_NAME | TYPE NOUN | CONTEXT NOUNS | LOCATION nvt | |')
LETOP: wanneer je de scanner op een bestaande tabel uitvoert, kan het zijn dat de gevonden waarden te groot zijn voor de target-tabel. Deze kolommen van tabel
dient dan vervolgens uitgebreid te worden
Plotters
Middels eenvoudige plotfuncties kan de dataset van een view eenvoudig visueel gemaakt om te kijken de view data naar verwachting geeft. Er zijn 3 typen grafieken: kind = line,bar,scatter
plot_query ('| QUERY select top 10 * from xxx.grip_aud | KIND scatter | X_AS fie | Y_AS elapse |')
plot_query ('| QUERY select top 1000 * from xxx.grip_aud | KIND scatter | X_AS fie | Y_AS sel |')
plot_query ('| QUERY select fie, sum(1) aantal from xxx.grip_aud group by fie | KIND bar | X_AS FIE | Y_AS AANTAL |')
- TYPE : [ HBAR,PIE,PIE1 ]
- QUERY : Query for values and dimension ( eg. select value, color from dual )
- XLABEL : label for X-axes
- TITLE : title of graph
plot('| TITLE ETL-functions used | QUERY select fie ETL_function , sum(1) aantal from xxx.grip_aud group by fie | TYPE HBAR | XLABEL number of calls | ')
plot('| TITLE ETL-functions used | QUERY select fie, sum(1) aantal from xxx.grip_aud group by fie | TYPE PIE | XLABEL number of calls | ')
plot('| TITLE ETL-functions used | QUERY select fie, sum(1) aantal from xxx.grip_aud group by fie | TYPE PIE1 | XLABEL number of calls | ')
TableCompare
Met de tablecompare kunnen 2 tabellen van gelijke structuur met elkaar vergeleken worden. Eventueel kan middels views de 2 tabellen gelijkgetrokken worden van structuur ...
In het volgende wordt middels een knip-en-plak voorbeeld de routine uitgelegd :
--stap1: maak 2 temp-tabellen
trunc_insert( '| SOURCE GRIP_METADATA_V | TARGET TABLECOMP1a | ' )
trunc_insert( '| SOURCE GRIP_METADATA_V | TARGET TABLECOMP1b | ' )
--stap2: breng verschil aan
UPDATE xxx.TABLECOMP1a set TABLE_TYPE = 'table' where TABLE_NAME = 'TABLECOMP1A'
--stap3: aanschouw het verschil.
SELECT * from xxx.TABLECOMP1A where TABLE_NAME = 'TABLECOMP1A'
--stap4: voer de compare uit:
table_compare( '| SOURCE TABLECOMP1A | TARGET TABLECOMP1B | MERGE_KEYS SCHEMA_NAME,TABLE_NAME,COLUMN_NAME | NOCLEANUP | xDEBUG| SHOWRES | ' )
--stap5: kijk in de grip_log naar wat er voor ETL-bewerkingen is gegenereerd
SELECT top 10 info, a.* from xxx.grip_log a order by id desc
--stap6: in tabel '_TC' zie je de verschillen gegroepeerd
SELECT * from xxx.TABLECOMP1A_TC
--stap7: in tabel '_TC1' de combinatie errors per attributen
SELECT * from xxx.TABLECOMP1A_TC1
--stap8: in tabel '_TC2' de combinatie errors
SELECT * from xxx.TABLECOMP1A_TC2
--stap9: hoeveelheid fouten per attribuutcombinatie
SELECT * from xxx.TABLECOMP1A_TC3
--stap10: overzicht van de gegenereerde code
SHOW CODE
SHOW GRIP_LOG GRIP_AUD GRIP_AUD
Azure
Een sql-database in Azure laat zich net zo bedienen als een on-premise database. Alle standaard GRIP-etl functies werken op de database maar voor data naar Azure te pompen, zijn er speciale GRIP-azure-functies ontwikkeld. Het betreft functies voor csv-data naar de cloud-storage te copieren. Zodra de csv-bestanden in de blob-storage aanwezig is, kan middels de BULK COPY heel snel data in de tabellen geladen worden.
Om GRIP met AZURE te laten samenwerken dient in de AZURE-portal enkele voorbereidingen getroffen te worden :
- Het AZURE account
- Een sql-database
- Een blob-storage
- Een blob-container.
Wanneer deze items aanwezig zijn, dienen wat parameters in de grip_con.dat opgenomen te worden voor het koppelen aan de blob-storage. Deze parameters kunnen toegevoegd worden aan de AZURE-connection. De parameters connectstring,blobkey,containerlocation kunnen allemaal vanuit de azure portal gegenereed en gecopieerd worden. Letop de geldigheidsperiode bij blobkey. Wanneer de geldigheidsperiode verlopen is, krijg je een permission-error en dien je een nieuwe blobkey te genereren met een nieuwe geldigheidsperiode. De masterkey is het wachtwoord voor het genereren van een DATABASE masterkey.
masterkey = GripOpDataPassword@#&
connectstring = DefaultEndpointsProtocol=https;AccountName=storagecsv123;AccountKey=o4SjRriJGLkBd4CDr1v9Nhc7jJNFYzbl0ggN3CCfFbQAalQTob5Q==;EndpointSuffix=core.windows.net
blobkey = sp=r&st=2021-04-04T08:51:22Z&se=2021-09-01T16:51:22Z&spr=https&sv=2020-02-10&sr=c&sig=51LOii%Sti7nweptH5zaTwYM2o3YZKWYDywPPo%3D
containerlocation = https://storagecsv123.blob.core.windows.net/gripcontainer
De volgende functies zijn gedefinieerd:
- azure('| ACTION INFO | CONTAINER gripcontainer |')
display van de azure parameters, zoals deze in de grip_con.dat gedefinieerd zijn.
- azure ('| ACTION INIT | CONTAINER gripcontainer |')
Aanmaak van de GRIP-componenten voor koppelen van GRIP met de CLOUD-storage. Deze koppeling behoeft niet opgeruimd te worden en kan steeds gebruikt worden voor de gekozen storage-blob.
Busy...
[AZURE,grip_azure,INFO] Create External Data Source .
[AZURE,grip_azure,INFO] CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'GripOpDataPassword@#&'
[AZURE,grip_azure,INFO] CREATE DATABASE SCOPED CREDENTIAL MyGripAzureBlobStorageCredential
WITH IDENTITY = 'SHARED ACCESS SIGNATURE',
SECRET = 'sp=r&st=2021-04-04T08:51:22Z&se=2021-09-01T16:51:22Z&spr=https&sv=2020-02-10&sr=c&sig=51LOii% TwYM2o3Y DywPPo%3D'
[AZURE,grip_azure,INFO] CREATE EXTERNAL DATA SOURCE dataset WITH
( TYPE = BLOB_STORAGE, LOCATION = 'https://storagecsv123.blob.core.windows.net/gripcontainer', CREDENTIAL= MyGripAzureBlobStorageCredential )
Ready ......(0.8)...........
- azure ('| ACTION FINIT | CONTAINER gripcontainer |')
Met dit commando kan de connectie opgeruimd worden om bijvoorbeeld te connecten met een andere storage-blob.
Busy...
[AZURE,grip_azure,INFO] Cleanup External Data Source .
[AZURE,grip_azure,INFO] drop EXTERNAL DATA SOURCE dataset .
[AZURE,grip_azure,INFO] drop DATABASE SCOPED CREDENTIAL MyGripAzureBlobStorageCredential .
[AZURE,grip_azure,INFO] drop MASTER KEY .
Ready ......(0.6)...........
- azure('| FILE customers.csv | DIRECTORY .\data | ACTION PUT | CONTAINER gripcontainer |')
Met dit commando wordt het csv-bestand naar de storage-blob gekopieerd. Een eventueel aanwezig gelijknamig bestand wordt vooraf verwijderd.
Ready ......(0.6)...........
Busy...
[AZURE,grip_azure,INFO] Uploading .\data\customers.csv --> customers.csv (gripcontainer)
Ready ......(0.7)...........
- azure('| FILE customers.csv | DIRECTORY ./data | ACTION DELETE | CONTAINER gripcontainer |')
Voor het verwijderen van een bestand in de blob-storage.
- azure('| DIRECTORY .\data | ACTION GET* | CONTAINER gripcontainer |')
Voor het downloaden van alle bestanden vanuit de storage-blob naar je lokale pc.
Busy...
[AZURE,grip_azure,INFO] Use gripcontainer
[AZURE,grip_azure,INFO] Listing storage gripcontainer
[AZURE,grip_azure,INFO] Copy files from blob to local:gripcontainer -> DMT_D_ARTIKEL.csv
[AZURE,grip_azure,INFO] Copy files from blob to local:gripcontainer -> GRIP_LOG_00002.csv
[AZURE,grip_azure,INFO] Copy files from blob to local:gripcontainer -> OraGrip2.dict
[AZURE,grip_azure,INFO] Copy files from blob to local:gripcontainer -> gekvoert.csv
Ready ......(35.9)...........
- azure('| ACTION INSERT | SOURCE c:/data/customers.csv | TARGET customer| DELIMITER , | CONTAINER gripcontainer |')
Met deze routine wordt eerst de SOURCE naar de gripcontainer gecopieerd. Vervolgens wordt , indien de targettabel niet bestaat ,de target_tabel aangemaakt op basis van een sampling van de data. Daarna wordt de tabel gevuld met de data van de csv. Mogelijk kan er toch nog een attribuut te klein zijn: deze kan eenvoudig vergroot worden.
Datavault
View GRIP_METADATA_V wordt als bron gebruikt voor de actualize_hub('') in ons voorbeeld. De view bestaat met de installatie van GRIP, in het grip_schema conforn de connectie-definitie.
Middels MERGE_KEYS, ofwel de business-keys, wordt aangegeven wat de business-key is van de HUB. De business-key mag uit meerdere attributen bestaan
en kan bijvoorbeeld een nietszeggend ID zijn, maar een betere keuze zou een functioneler attribuut zijn.
Deze attributen mogen NIET null-values bevatten.
De overige aangeboden attributen die de aanleverview aanbiedt, welke dus geen deeluitmaken van de MERGE_KEYS, komen in de satelite terecht. De satelite van de link en hub worden tiepe-2
ververst.
De Unique-key's, Primary-keys en Foreignkeys tussen de satelite en hub worden bij aanmaak van de tabellen gegenereerd.
Indien je de hub vanuit een andere bron ververst, middels een andere aanlever-view, dient deze actualisatie-view dezelfde MERGE_KEYS aan te leveren.
Wanneer de overige attributen bewaard dienen te worden maar anders zijn dan de reeds bestaande satelite, kan een nieuwe satelite gedefineerd worden
waar de overige attributen tiepe-2 in opgelagen worden.
Algemeen geldt: de attributen die je via de aanleverview aanbiedt, worden verdeeld over de hub en satelite. Indien je geen satelite ( SAT_IS ) opgeeft, wordt er geen satelite ( meer ) bijgewerkt vanuit die etl-aanroep.
actualize_hub ( '| SOURCE GRIP_METADATA_V | TARGET H_OBJECTS | SAT_IS HS_OBJECTS | MERGE_KEYS SCHEMA_NAME,TABLE_NAME,COLUMN_NAME | ')
-- drop table xxx.HS_OBJECTS
-- drop table xxx.H_OBJECTS
De actualize_link('') is voor de relatie tussen de hubs. De link kan eveneens een of meerdere satelites hebben, en wordt eveneens middels een actualisatie-view ververst. Met de '| SAT_IS satelite |' wordt de satelite van de link aangemaakt en steeds ververst. De link-aanleverview dient alle attributen aan te leveren gelijk aan de sommatie van de MERGE_KEYS van de hubs. Indien met een HUB uit de hub_list een alias gebruikt wordt, dient de alias als prefix voor de merge_keys geplaatst te worden. Om dit te verduidelijken wordt de createscript van de link-aanleverview getoond :
drop VIEW xxx.grip_metadata_lv
CREATE VIEW xxx.grip_metadata_lv AS
SELECT DISTINCT
a.schema_name, -- voor de eerste hub
a.table_name, -- voor de eerste hub
a.column_name, -- voor de eerste hub
a.schema_name AS h2_schema_name, -- voor de tweede hub
a.table_name AS h2_table_name, -- voor de tweede hub
a.column_name AS h2_column_name, -- voor de tweede hub
a.schema_name AS h3_schema_name, -- voor de derde hub
a.table_name AS h3_table_name, -- voor de derde hub
a.column_name AS h3_column_name, -- voor de derde hub
'JANSONIUS' AS naam, -- voor de satelite
1234 AS numero, -- voor de satelite
CURRENT_TIMESTAMP AS datum -- voor de satelite
FROM xxx.grip_metadata_v a
actualize_link ( '| SOURCE GRIP_METADATA_LV | TARGET L_OBJECTS | SAT_IS LS_OBJECTS | HUB_LIST H_OBJECTS, H_OBJECTS H2, H_OBJECTS H3 |')
-- drop table xxx.LS_OBJECTS
-- drop table xxx.L_OBJECTS
De Unique-key's, Primary-keys en Foreignkeys tussen de link en satelite en hubs worden bij aanmaak van de tabellen gegenereerd.
Voor zowel de hub als de link kan optioneel in de aanleverview de attributen SOURCE_NAME, LOAD_DTS en END_LOAD_DTS opgegeven worden.
- SOURCE_NAME voor de functionele naam van de bron, bij afwezigheid vult GRIP hiervoor de naam van de view in.
- LOAD_DTS voor het functionele tijdstip van creatie van de link of hub, anders vult GRIP hiervoor het tijdstip van laden van aanroep
- END_LOAD_DTS voor het functionele tijdstip van afsluiten van de link of hub, anders vult GRIP dit attribuut bij het laden met waarde NULL
te gebruiken parameters:
- SHOWCODE : toon na succesvol einde alle gegenereerde code
- DEBUG 3 : toon tijdens generatie de code, geen value betekent alles, 1 = specifieke ETL-code, value 3 levert tevens de proces-code
- SHOWRES : toon na afloop het log-resultaat in grip_log en grip_aud.
- NOCLEANUP : middels deze parameter worden de temp-tabellen niet opgeruimd
- SKIP_COLS : lijst met de skippen attributen
- WHERE : de where clause
Met de mail-functie kan bijvoorbeeld een beheer geinformeerd worden indien er een ETL in de error raakt. Indien de mail geconfigureerd is, middels de win.ini, gaat dat vanzelf. De mail die toegestuurd wordt, bevat relevante info voor het oplossen van de fout, zoals de logging van de ETL, het ETL-statement welke fout ging.. Met de mail krijgt de beheerder alle info voor het oplossen van het probleem. E.e.a. zal pas werken nadat de grip_mail.ini goed is ingevuld. Verderop is een voorbeeld van de inhoud van de grip_mail.in weergegeven.
Maar de mail kan ook gebruikt worden voor :
- versturen van CSV-bestanden als bijlage naar gebruikers,
- versturen van HTML-mails voor rapportage-doeleinden,
- mailen van mailings naar gebruikers/klanten
mail('| SUBJECT Onderwerp 123 | MESSAGE Testmail 123 | TO MAIL_BEHEER | BIJLAGE grip_con.dat,grip.py,grip_flh.py | ')
mail('| SOURCE grip_sched | SUBJECT Onderwerp 123 | MESSAGE test 123 | FROM dolf@gripopdata.nl | TO dolf@gripopdata.nl | BIJLAGE grip_con.dat,grip.py,grip_flh.py |')
middels deze parameters wordt de mail geinitieerd.
SET PARA MAIL_TO CHAR dolf@gripopdata.nl
SET PARA MAIL_FROM CHAR info@gripopdata.nl
SET PARA MAIL_BEHEER CHAR gripondata@gmail.com
select * from grip.grip_para where code like 'MAIL%'
SUBJECT : onderwerp
MESSAGE : body van de email
HTML : html-text of naam van bestand
OUTPUT : ntb
BIJLAGE : lijst met bestanden
SOURCE : sql-query
TO : mail naar ...
FROM : mail van ..
DIRECORY : ntb
csv2mail
nb: de TO en FROM gaan via de parameters MAIL_TO en MAIL_FROM en behoeven daarom niet
opgegeven te worden.
csv2mail('| SOURCE select * from xxx.grip_debug | WHERE 2=2 | SUBJECT Overzicht debug-gegevens| MESSAGE Bijlage bevat de gegevens van de tabel grip_debug | ||')
csv2mail('| SOURCE grip_sched | SUBJECT Scheduler-gegevens | MESSAGE inhoud van de scheduler | ||')
Met deze functie wordt de dataset van de query als csv-bijlage verzonden.
De eerste regel bevat de header.
etl ('| MAIL |')
Met het prototypen van een ETL kan als command 'MAIL' toegevoegd worden. Indien de ETL bijvoorbeeld 20 minuten duurt, wordt na beeindigen van de ETL een email verstuurd met logging-informatie van deze ETL. Onderdeel daarvan is o.a. hoeveel records, doorloop en welke ETL's nog meer op deze target_tabel van toepassing zijn. Indien deze ETL in een error komt, vanuit een flow, wordt er automatisch een mail gestuurd met relevante debug-informatie zoals de gegenereerde SQL-query waar de error op van toepassing is.
trunc_insert ('| SOURCE GRIP_METADATA_V | TARGET METADATA_DEMO1 | 2SCHED | MAIL | ')
de grip_mail.ini bevat volgende regels. Pas de parameters aan op uw situatie.
[smtp]
smtp_server = smtp.gmail.com
smtp_port = 587
smtp_user = GripOpMail@gmail.com
smtp_password = Uwwachtwoord!!@@
Sql
Voor de databases Oracle,Postgresql,Snowflake en Sqlserver kan sql-queries of commando's in de editor ingevoerd worden waarna ze geexecuteerd kunnen worden middels het selecteren van de sql en vervolgens op de button 'execute' te clicken. Wil men de sql via een 'procedure' aanroepen, kan dat door om het sql-statement 'QRY' en 'EXEC;' te plaatsen. De SQL moet voldoen aan de syntax van de geselecteerde database.
QRY
select *
from table
where sysdate > date_created
SHOW;
QRY
drop table tab1
EXEC;
Show
Met SHOW kan info verkregen worden van connectie, createscript, flows, logdata e.d.
Voer onderstaand commando's uit om het resultaat ervan te beleven:
SHOW CON
SHOW CONN
SHOW DBF
SHOW DATA xxx.grip_log
SHOW DATA xxx.grip_sched
SHOW DATA xxx.cbs_opendata
SHOW CODE
SHOW META
SHOW META AIR
SHOW META AIR GRIP
SHOW FLOW
SHOW FLOWS
SHOW FLOW ALL
SHOW FLOW RUN
SHOW FLOW DEF
SHOW PARA ALL
SHOW PARA WOONPLAATS
SHOW DDL GRIP_LOG GRIP_DEBUG GRIP_SCHED
SHOW DICT STG_AIR
SHOW DICT STG_AIR GRIP
SHOW GRIP_AUD GRIP_LOG
SHOW CURRENT_DIR
SHOW SELECT GRIP_LOG
Set
SET DBF
SET PARA DEMO CHAR inhoud van de char
SET PARA DEMO NUM 9712
SET PARA DEMO DATE 2021-04-01
SET PARA DEMO DESC 'gripopdata'
Cat
Zoals de unix-cat: De eerste 10 regels worden getoond, om een beeld te krijgen van bv. de csv-data. Een optionele tweede parameter geeft het aantal regels aan. Deze is default 10.
CAT c:/data/AIRLINES.csv 10
Busy...
"CUSTOMER_NUMBER","PREFIX_IATA_2","PREFIX_IATA_3","AIRLINE_NAME_LONG","AIRLINE_NAME_SHORT","AIRLINE_NAME_PUBLIC","CASH_INDICATOR","VAT_INDICATOR","HOME_CARRIER_INDICATOR","ALLIANCE_PAX","MARKET_SECTOR_PAX","LEGAL_GROUP_PAX","ACCOUNT_GROUP_PAX","ACCOUNT_MANAGER_PAX","ALLIANCE_CARGO","MARKET_SECTOR_CARGO","LEGAL_GROUP_CARGO","ACCOUNT_GROUP_CARGO","ACCOUNT_MANAGER_CARGO","RESPONSIBLE","MUTATION_CODE","CNT_COUNTRY_NUMBER","DATETIME_LAST_CHANGED","TIMESTAMP_INSERT","P_WEEKDAY","CODE_NVLS"
"4407","1B","BGH","Balkan Holiday Airlines","BH Air","Balkan Holiday Airlines","N","N","N","","","","","","","","","","","MD/MF","UPD",,02-JUL-12,"20120702 11:45:08:351922000","2","232"
"26583","","FAH","Farnair Europe / Farner Air Transport Hungary","Farnair Europe","Farnair Europe / Farner Air Transport Hungary","Y","N","N","","","","","","","","","","","","UPD",,02-JUL-12,"20120702 13:42:29:827669000","2","1878"
"10118","CE","MSC","Air Cairo","Air Cairo","Air Cairo","N","N","N","","","","","","","","","","","","UPD",,02-JUL-12,"20120702 15:15:35:287583000","2","4828"
"1777","GA","GIA","Garuda Indonesian Airways","Garuda","Garuda Indonesia","N","N","N","","","","","","","","","","","","UPD",,16-JUL-12,"20120716 08:46:32:794117000","2","85"
"5514","","SXA","Southern Cross Aviation","Southern Cross","Southern Cross Aviation","Y","N","N","","","","","","","","","","","","UPD",,16-JUL-12,"20120716 16:41:49:385606000","2","4130"
"15342","EK","UAE","Emirates","Emirates","Emirates","N","N","N","","","","","","","","","","","Emirates","UPD",,06-AUG-12,"20120806 09:24:41:965459000","2","4913"
"6722","7D","UDC","Donbassaero","Donbassaero","Donbassaero","Y","N","N","","","","","","","","","","","","UPD",141,06-AUG-12,"20120806 09:32:11:007198000","2","542"
"13025","","TWI","Tailwind","Tailwind","Tailwind","N","N","N","","","","","","","","","","","NB","UPD",,06-AUG-12,"20120806 10:20:20:552312000","2","4886"
"1840","KL","KLM","Koninklijke Luchtvaart Mij NV","KLM","KLM","N","N","N","","","","","","","","","","","PF/IG","UPD",,22-OCT-12,"20121022 13:22:12:591921000","2","100"
Ready ......(0.0)...........
Dir
Voor het lijsten van de inhoud van een directory .
dir c:/data
add_conn
runtime toevoegen van connections
add_conn ('| CONNECTION ROSS | MESSAGE PG Ross| SERVER 136.243.88.122 | PORT 5432 | DATABASE ROSS
| USERNAME kijker | SCHEMA prod| GRIP_SCHEMA grip | PASSWORD xxx
| ODBCDSN {PostgreSQL ANSI(x64)} | CON_TYPE postgresql | ')
Metadata
In het kader van ETL-automation, kan middels de functie METADATA o.a. ETL-calls gegenereerd worden. Via view GRIP_METADATA_V worden de tabellen en views getoond waar de current connectie select-rechten toe heeft.
METADATA | WHERE TABLE_NAME like '%AIR%' | DEBUG |
METADATA | WHERE TABLE_NAME like '%AIR%' | SHOW DDL |
METADATA | WHERE TABLE_NAME like '%AIR%' | DROP |
METADATA | WHERE TABLE_NAME like '%AIR%' | DATA |
METADATA | WHERE TABLE_NAME like '%AIR%' | LIST |
METADATA | WHERE TABLE_NAME like '%A%' | TEMPLATE drop <SCHEMA>.<TYPE> <OBJECT> |
METADATA | WHERE TABLE_TYPE = 'VIEW' | TEMPLATE trunc_insert_ss('! SOURCE <OBJECT> ! TARGET <OBJECT> !') |
Graphviz
Graph visualization is a way of representing structural information as diagrams of abstract graphs and networks. Automatic graph drawing has many important applications in software engineering, database and web design, networking, and in visual interfaces for many other domains
Graphviz is open source graph visualization software. It has several main graph layout programs. See the galleryfor some sample layouts. It also has web and interactive graphical interfaces, and auxiliary tools, libraries, and language bindings.
Graphviz kun je eenvoudig downloaden en middels de handleiding is makkelijk te doorgronden hoe de taal werkt. In Graphvizonline kun je experimenteren met Graphviz.
graph_jobs ( '| QUERY select distinct source p , target c from xxx.grip_aud |' )
graph_jobs ( '| QUERY select source, target from xxx.grip_aud |' )
Beheer
StartUp en connectie
Voor het inrichten van een warehouse-database-omgeving ( in bijvoorbeeld sqlserver ) is gebruikelijk de schema's STAGE, ODS en DATAMART te hanteren. In STAGE staan de tabellen voor bron-replicatie. Indien er meerdere bronnen zijn, en indien men kiest voor een stage-schema per bron, kan men dat eenvoudig inregelen. In de ODS tref je vaak de STAGE tabellen weer aan, bronvolgend, maar met historie. In de MRT laag komen meestal de business-volgende ster-modellen.
BRON --> STAGE --> ODS --> MRT
data
- aanmaak database, schema's en connecties
create database grip_warehouse
use grip_warehouse
create schema stage
create schema ods
create schema mart
create schema grip
NB:letop dat de user <gwh_login1> de schema's 'owned'. In 'grip_schema' worden de
grip-tabellen en views opgeslagen.
connection = logische naam van de connectie
message = logische naam voor voortgangscherm bv .. Connecting to GRIP_WAREHOUSE_grip ( )....
server = ipnummer of host ( is te pingen )
port = poortnummer 1433 of 1521, moet openstaan in de firewall
database = database of SID naam, bv GRIP_WAREHOUSE
schema = schema of username. Een oracle-schema wijkt af van een Sqlserver schema
grip_schema = schema voor de grip-tabellen en views en sequence
username = login naam (= schema naam / username )
password = wachtwoord
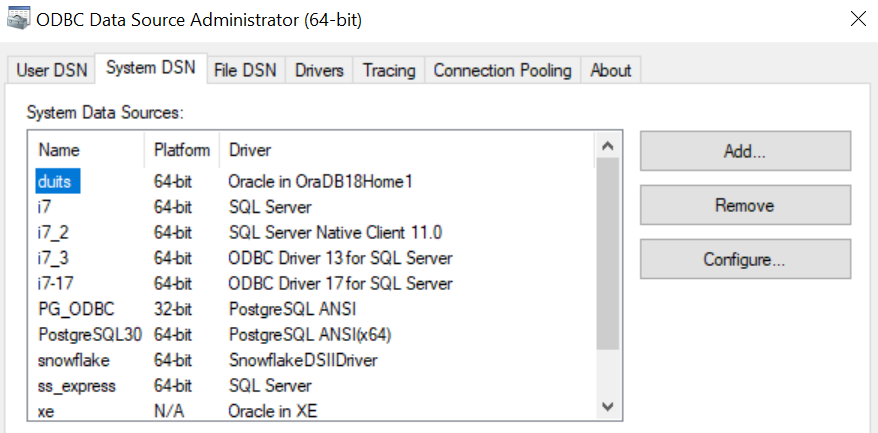
odbcDsn = tussen de {} de naam van de driver in odbcadmin {ODBC Driver 17 for SQL Server}
con_type = de type database bepaalt de SQL dialect.. ( sqlserver,postgresql,oracle,snowflake )
connection = GW_grip
message = Connecting to GRIP_WAREHOUSE_grip ( voor grip-logging )....
server = 82.73.202.254
port = 1433
database = GRIP_WAREHOUSE
schema = grip
grip_schema = grip
username = gwh_login1
password = gwh_login_1
odbcDsn = {ODBC Driver 17 for SQL Server}
con_type = sqlserver
connection = GW_STAGE
message = Connecting to GRIP_WAREHOUSE_stage ....
server = 82.73.202.254
port = 1433
database = GRIP_WAREHOUSE
schema = stage
grip_schema = grip
username = gwh_login1
password = gwh_login_1
odbcDsn = {ODBC Driver 17 for SQL Server}
con_type = sqlserver
connection = GW_ODS
message = Connecting to GRIP_WAREHOUSE_ods ....
server = 82.73.202.254
port = 1433
database = GRIP_WAREHOUSE
schema = ods
grip_schema = grip
username = gwh_login1
password = gwh_login_1
odbcDsn = {ODBC Driver 17 for SQL Server}
con_type = sqlserver
connection = GW_MART
message = Connecting to GRIP_WAREHOUSE_mart ....
server = 82.73.202.254
port = 1433
database = GRIP_WAREHOUSE
schema = mart
grip_schema = grip
username = gwh_login1
password = gwh_login_1
odbcDsn = {ODBC Driver 17 for SQL Server}
con_type = sqlserver
Connectie voor oracle
connection = OraGrip2
message = Connecting to Oracle grip2 ....
server = 136.243.88.222
database = DB11G
schema = grip2
grip_schema = grip2
username = grip2
port = 1521
password = grip2
odbcDsn = {Oracle in OraDB18Home1}
con_type = oracle
Connectie voor postgresql
connection = postgresql
message = Connecting to Postgresql laptop .... LETOP !! geen
server = localhost
database = GRIP
username = postgres
schema = grip
grip_schema = grip
password = gripopdata
odbcDsn = {PostgreSQL ANSI(x64)}
con_type = postgresql
Connectie voor Snowflake
connection = snowflake
message = Connecting to Snowflake 4 ....
server = sm07120.europe-west4.gcp.snowflakecomputing.com
account = sm07120.europe-west4.gcp
database = GRIP
schema = grip
grip_schema = grip
username = janso001
password = Cm3dkW9vuySXz3z
warehouse = compute_wh
role = sysadmin
odbcDsn = {SnowflakeDSIIDriver}
con_type = snowflake
Aanmaak van een schema of database of user.
Ieder DBMS hanteert zijn eigen jargon en heeft zo zijn eigen invulling voor de begrippen user,schema,database en privileges ... Voor het gemak wordt voor ieder DBMS een basis set van scripts vermeld waarmee de GRIP-developper snel aan de bak kan !
** ORACLE **
CREATE USER <USER>
IDENTIFIED BY <PASSWORD>
DEFAULT TABLESPACE <TABLESPACE>
TEMPORARY TABLESPACE TEMP
PROFILE DEFAULT
ACCOUNT UNLOCK
--
ALTER USER <USER> QUOTA unlimited ON <TABLESPACE>;
GRANT CREATE ANY SYNONYM TO <USER>;
GRANT CREATE DATABASE LINK TO <USER>;
GRANT CREATE SEQUENCE TO <USER>;
GRANT CREATE SESSION TO <USER>;
GRANT CREATE SYNONYM TO <USER>;
GRANT CREATE TABLE TO <USER>;
GRANT CREATE VIEW TO <USER>;
GRANT CREATE PROCEDURE TO <USER>;
** speciale hint-opties **
SET PARA GRIP_CTAS_OPTION CHAR parallel (degree 6) unrecoverable
SET PARA GRIP_APPEND_HINT CHAR /*+ APPEND PARALLEL NOLOGGING */
actualize('| SOURCE | TARGET | HINTS | SHOWETL |')
middels HINTS wordt de hint-optie geactiveerd. De waarden van GRIP_CTAS_OPTION en GRIP_APPEND_HINT worden vervolgens in de statements geplaatst.
afhankelijk van het platform kan de juiste hint uitgeprobeerd worden.
** SQLSERVER **
create ...
USE [master]
GO
/****** Object: Database [grip_datawarehouse] Script Date: 21/10/2021 14:50:38 ******/
CREATE DATABASE [grip_datawarehouse]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'grip_datawarehouse', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL13.SQLEXPRESS\MSSQL\DATA\grip_datawarehouse.mdf' , SIZE = 73728KB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB )
LOG ON
( NAME = N'grip_datawarehouse_log', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL13.SQLEXPRESS\MSSQL\DATA\grip_datawarehouse_log.ldf' , SIZE = 466944KB , MAXSIZE = 2048GB , FILEGROWTH = 65536KB )
GO
IF (1 = FULLTEXTSERVICEPROPERTY('IsFullTextInstalled'))
begin
EXEC [grip_datawarehouse].[dbo].[sp_fulltext_database] @action = 'enable'
end
GO
/* For security reasons the login is created disabled and with a random password. */
/****** Object: Login [grip] Script Date: 21/10/2021 14:53:25 ******/
CREATE LOGIN [grip] WITH PASSWORD=N'SBimH1Q5T6gQxRaKQHn5M3JOuAXuLPdVTDoT8WG7uig=', DEFAULT_DATABASE=[master], DEFAULT_LANGUAGE=[us_english], CHECK_EXPIRATION=ON, CHECK_POLICY=ON
GO
ALTER LOGIN [grip] DISABLE
GO
** POSTGRESQL **
create ...
** SNOWFLAKE **
create ...
** MYSQL **
create ...
** MARIADB **
create ...
Versie Beheer
Datawarehouses gebouwd met GRIP, zijn gebasseerd op SQL-views en enkele scripts met de GRIP-ETL-aanroepen/procedures. In deze scripts worden de benodigde ETL-aanroepen gedefinieerd, met daarin de aanroep van de ETL-views. Tevens wordt in deze scripts de FLOWS gedefineerd en de scheduler. Meer sources zijn er niet.
- txtfiles_2_dbf() voor versiebeheer op ascii-bestanden of sources
- views_2_dbf () voor versiebeheer op de views ( create-scripts )
De txtfiles worden middels een wildcard gescanned en ingelezen. Van de views wordt een create-script verwerkt. De sources worden opgeslagen in de tabel GRIP_SOURCE. Hierna wordt de inhoud van GRIP_SOURCE verwerkt in GRIP_SOURCE_HIST. In deze laatste tabel zit de programmatuur tiepe-2 opgeslagen: de views en sources zijn hierin incrementeel opgeslagen in de tijd. Middels een pijldatum kan een specifieke source teruggehaald worden uit GRIP_SOURCE_HIST.
- In de grip_source zit de actuele code en createscripts
- in de grip_source_hist zit de wijzigingshistorie van de code. In deze tabel kun je middels een pijldatum de create-scripts reconstrueren van bv 3 weken terug
BEGIN VERSIE_BEHEER
SET DBF postgresql
DISP Letop: Versiebeheer in alleen de locale postgresql database.
txtfiles_2_dbf( r'| SOURCE <CURRENT_DIR> | xDEBUG 3 | WILDCARD *.dat | LABEL BESTANDEN | CONTEXT CONNECTIE_DATA | ')
views_2_dbf( '| LOG_INFO t2-versiebeheer van de views van current-schema | LABEL ETL_VIEWS | CONTEXT DEMO_VIEWS | ')
# select * from xxx.grip_source
# select * from xxx.grip_source_hist
# delete from xxx.grip_source
# delete from xxx.grip_source_hist
select source,location, label,context, sum(1) aantal
from xxx.grip_source
group by location, label,context, source
order by label,source,location, context
select location, label,context, sum(1) aantal
from xxx.grip_source
group by location, label,context
order by context,location,label
select b.vrs, a.*
from xxx.grip_source_hist a
, ( select row_number() over ( partition by 1 order by date_created desc ) vrs
, date_created versie_datum
, sum(1)
from xxx.grip_source_hist
group by date_created
) b
where b.versie_datum between a.date_created and coalesce(a.date_deleted,a.date_created )
and source = 'grip_con.dat'
and vrs = 10
order by vrs, regelnr
CALL PF_VERSIEBEHEER
BEGIN PF_VERSIEBEHEER
txtfiles_2_dbf( r'| SOURCE <CURRENT_DIR> | xDEBUG 3 | WILDCARD *.dat | xNOCLEANUP | CONTEXT Code | ')
views_2_dbf( '| LOG_INFO t2-versiebeheer van de views van current-schema |')
DISP overzicht objecten in versie
QRY
select source,location, label,context, sum(1) aantal
from xxx.grip_source
group by location, label,context, source
order by label,source,location, context
SHOW;
QRY
select location, label,context, sum(1) aantal
from xxx.grip_source
group by location, label,context
order by context,location,label
SHOW;
RETURN
Lineage
Diagonaal, verticaal en horizontaal zoeken door de code en views ... Wanneer middels versiebeheer de tabellen GRIP_SOURCE en GRIP_SOURCE_HIST gevuld zijn, kan heel eenvoudig in deze tabellen gezocht worden naar bijvoorbeeld een tabel-naam.
postgresql :
select * from xxx.GRIP_SOURCE where position ('DELIMITER' in regel) > 0

Aanroep GRIP.exe
Tijdens het starten van GRIP worden eerst wat bestanden klaargezet / uitgepakt in de temp-directory van de user. Dit neemt een paar seconden. Daarna reageert GRIP snel op de commando's. GRIP enkele dagen aan laten staan an geen kwaad: verbroken verbindingen worden weer hersteld, en GRIP gaat verder me waar hij was. De code in de editor wordt altijd vooraf gesaven, zodat er nooit werk verloren gaat.
GRIP.exe kan op een 4-tal manieren aangeroepen worden. Het aanroepen kan vanaf de commandline, vanuit een batch-file of vanuit de windows-scheduler.
- gui aanroep van GRIP met command-file 'grip_calls' in de editor.
- file aanroep van GRIP waarbij GRIP een file opent en vervolgens de code van een LABEL uit gaat voeren
- exec aanroep van GRIP met commando '| COMMAND xxx | CONNECTION snowflake |'
- scheduler
Aanroepen vanaf de cmd-commandline of vanuit een batchfile of vanuit de windows-scheduler :
grip.exe -m gui -f grip_calls
grip.exe -m exec -l "| COMMAND SLEEP 10| CONNECTION snowflake |"
grip.exe -m file -f grip_calls -l PF_HUGO
-m gui -f {script}
Met deze aanroep wordt de editor opgestart met daarin het opgegeven bestand geopend voor aanpassing of uitvoer van de statements. Het bestand moet zich bevinden in de current-directory, dus waar de grip.exe ook staat. Naamgeving is niet case-sensitive.Zodra de editor actief is, kan een éénregel-commando uitgevoerd worden middels ctrl-enter of een of meerdere regels selecteren en vervolgens op de execute-button te clicken.
grip.exe -m gui -f grip_calls
-m exec -l {COMMAND}
Commando's die een database benaderen voor metadata, zoals een FLOW, moeten wel weten in welke database/connectie zij moeten zoeken. Middels CONNECTION kan de connectie opgegeven worden. Tijdens de startup zal de connection in de GRIP_CON.dat aanwezig moeten zijn .
grip.exe -m exec -l "| COMMAND SLEEP 10 |"
grip.exe -m exec -l "| COMMAND SLEEP 10 | CONNECTION snowflake |"
grip.exe -m exec -l "| COMMAND flow_run('| FLOW PF_TESTFLOW |') | CONNECTION snowflake |"
grip.exe -m exec -l "| COMMAND flow_run('| FLOW PF_TESTFLOW |') | CONNECTION sqlserver |"
-m file -f -l
Deze aanroep kan vanuit de windows, vanaf de commandline of vanuit de windows-scheduler waarbij de file grip_calls aanwezig moet zijn in de directory van grip.exe en de procedure PF_MAIN_FLOW gevonden moet worden. Letop dat de juiste connection geselecteerd wordt ivm het processen in de juiste target-database.
grip.exe -m file -f grip_calls -l PF_MAIN_FLOW
Mkdocs
Middels het Mkdocs-commando kan technische documentatie gegenereerd worden. Mkdocs is een opensource faciliteit die veel ingezet wordt voor documentatie. Voor deze faciliteit dient wel mkdocs.exe gedownload te worden van de portal van gripopdata.nl.
mkdocs : genereren van de documentatie. e.e.a. wordt geplaatst achter de data/portal/
drop para MKDOCS_%
ADDITEM
# Inleiding van de website
Het doel van deze applicatie is het repliceren van de Bron CIMS met historie. Middels ETL-automation is de gehele
tabellenverzameling van CIMS naar de STAGE van BI_CIMS gerepliceerd. Kleine tabellen met een full-refresh en grotere tabellen
worden middels een delta verversd.
ADDITEM# Inleiding 1
ADDITEM
# Beheer
Het beheer wordt gedaan middels de grip-beheer-faciliteiten.
Op de website staan veel uitvraag-views voor JOBS,ETL e.d.
ADDITEM# Beheer 10
ADDITEM
# Organisatie
De volgende organisaties/afdelingen spelen een rol in de applicatie :
- GRIPOPDATA.nl
Dolf Jansonius, 06-54946006
Hugo Dissel, 06-
ADDITEM# Organisatie 11
ADDITEM
# Infra
- databases
- software
- accounts
-
ADDITEM# Infra 12